
4.9: Measure of Spread or Dispersion
- Page ID
- 5723
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Measures of Dispersion
Look at the graphs below. Each represents a collection of many data points and shows how the individual values (solid line) compare to the mean of the data set (dashed line). You can see that even though all three graphs have a common mean, the spread of the data differs from graph to graph. In statistics we use the word dispersion as a measure of how spread out the data is.
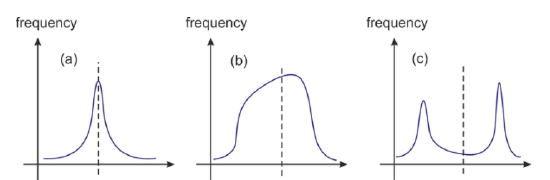
Range
Range is the simplest measure of dispersion. It is simply the total spread in the data, calculated by subtracting the smallest number in the group from the largest number.
Finding the Range
Find the range and the median of the following data:
223, 121, 227, 433, 122, 193, 397, 276, 303, 199, 197, 265, 366, 401, 222
The first thing to do in this case is to order the data, listing all values in ascending order:
121, 122, 193, 197, 199, 222, 223, 227, 265, 276, 303, 366, 397, 401, 433
Note: It is extremely important to make sure that you don’t skip any values when you reorder the list. Two ways to do this are (i) cross out the numbers in the original list as you write them in the second list, and (ii) count the number of values in both lists when you are done. In this example, both lists contain 15 values, so we can be sure we didn’t miss any (as long as we didn’t count any twice!)
The range is found by subtracting the lowest value from the highest: 433−122=311.
And now that the list is ordered, we can see that the median is the 8th value: 227.
Variance
The range is not a particularly good measure of dispersion, as it does not eliminate points that have unusually high or low values when compared to the rest of the data (the outliers). A better method involves measuring the distance each data point lies from a central average.
Look at the following data values:
11, 13, 14, 15, 19, 22, 24, 26
The mean of these values is 18; of course, the values all differ from 18 by varying amounts. Here’s a list of the values’ deviations from the mean:
-7, -5, -4, -3, 1, 4, 6, 8
If we take the mean of these deviations, we find that it is zero:
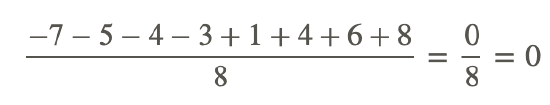
This comes as no surprise. You can see that some of the values are positive and some are negative, as the mean lies somewhere near the middle of the range. You can use algebra to prove (try it!) that the sum of the deviations will always be zero, no matter what numbers are in the list. So, the sum of the deviations is not a useful tool for measuring variance.
But if we square the differences, all the negative differences become positive, and then we can tell how great the average deviation is. If we do that for this data set, we get the following list:
49, 25, 16, 9, 1, 16, 36, 64
The sum of those squares is 216, so their average is 2168=27.
We call this averaging of the square of the differences from the mean (the mean squared deviation) the variance. The variance is a measure of the dispersion, and its value is lower for tightly grouped data than for widely spread data. In the example above, the variance is 27.
What does it mean to say that tightly grouped data will have a low variance? You can probably already imagine that the size of the variance also depends on the size of the data itself. Mathematicians have tried to standardize the definition of variance in various ways; the standard deviation is one of the most commonly used.
Standard Deviation
You can see from the previous example that using variance gives us a measure of the spread of the data (you should hopefully see that tightly grouped data would have a smaller mean squared deviation and so a smaller variance) but it is not immediately clear what a number like 27 actually refers to. Since it is the mean of the squares of the deviation, however, it seems logical that taking its square root would be a better way to make sense of it. The root mean square (i.e. square root of the variance) is called the standard deviation, and is given the symbol s.
Calculating the Mean, Variance, and Standard Deviation
Find the mean, the variance and the standard deviation of the following values.
121, 122, 193, 197, 199, 222, 223, 227, 265, 276, 303, 366, 397, 401, 433
The mean will be needed to find the variance, and from the variance we can determine the standard deviation. The sum of all fifteen values is 3945, so their mean is 3945/15=263.
The variance and standard deviation are often best calculated by constructing a table. Using this method, we enter the deviation and the square of the deviation for each separate data point.
| Value | Deviation | Deviation2 |
|---|---|---|
| 121 | –142 | 20,164 |
| 122 | –141 | 19,881 |
| 193 | –70 | 4,900 |
| 197 | –66 | 4,356 |
| 199 | –64 | 4,096 |
| 222 | –41 | 1,681 |
| 223 | –40 | 1,600 |
| 227 | –36 | 1,296 |
| 265 | 2 | 4 |
| 276 | 13 | 169 |
| 303 | 40 | 1,600 |
| 366 | 103 | 10,609 |
| 397 | 134 | 17,956 |
| 401 | 138 | 19,044 |
| 433 | 170 | 28,900 |
| sum: | 0 | 136,256 |
The variance is the mean of the squares of the deviations, so it is 136,256/15=9083.733. The standard deviation is the square root of the variance, or approximately 95.31.
If you look at the second column of the table, you can see that the standard deviation is a good measure of the spread. It looks to be a reasonable estimate of the average distance that each point lies from the mean.
Calculating and Interpreting Measures of Central Tendency and Dispersion for Real-World Situations
A number of house sales in a town in Arizona are listed below. Calculate the mean and median house price. Also calculate the standard deviation in sale price.
| Address | Sale Price |
|---|---|
| 518 CLEVELAND AVE | $117, 424 |
| 1808 MARKESE AVE | $128, 000 |
| 1770 WHITE AVE | $132, 485 |
| 1459 LINCOLN AVE | $77, 900 |
| 1462 ANNE AVE | $60, 000 |
| 2414 DIX HWY | $250, 000 |
| 1523 ANNE AVE | $110, 205 |
| 1763 MARKESE AVE | $70, 000 |
| 1460 CLEVELAND AVE | $111, 710 |
| 1478 MILL ST | $102, 646 |
The sum of all ten values is $1,160,370, so their mean is $116,037.
The median is halfway between the 5th and 6th highest values. Those two middle values (if we reorder the list by price) are $110,205 and $111,710, so the median is $110,957.50.
Now we can rewrite the table with the deviations and their squares added in:
| Value ($) | Deviation | Deviation2 |
|---|---|---|
| 60,000 | -56037 | 3140145369 |
| 70,000 | -46037 | 2119405369 |
| 77,900 | -38137 | 1454430769 |
| 102,646 | -13391 | 179318881 |
| 110,205 | -5832 | 34012224 |
| 111,710 | -4327 | 18722929 |
| 117,424 | 1387 | 1923769 |
| 128,000 | 11963 | 14311369 |
| 132,485 | 16448 | 270536704 |
| 250,000 | 133963 | 17946085369 |
| SUM: | 25178892752 |
The variation is 2517889275210=2517889275.2, and the square root of that is about 50179. So the standard deviation is $50,179.
In this case, the mean and the median are close to each other, indicating that the house prices in this area of Mesa are spread fairly symmetrically about the mean. Although there is one house that is significantly more expensive than the others, there are also a number that are cheaper to balance out the spread.
Example
Example 1
James and John both own fields in which they plant cabbages. James plants cabbages by hand, while John uses a machine to carefully control the distance between the cabbages. The diameters of each grower’s cabbages are measured. James’s cabbages have an average (mean) diameter of 7.10 inches with a standard deviation of 2.75 inches; John’s have a mean diameter of 6.85 inches with a standard deviation of 0.60 inches.
John claims his method of machine planting is better. James insists it is better to plant by hand. Use the data to provide a reason to justify both sides of the argument.
- James’s cabbages have a larger mean diameter, so on average they are larger than John’s. The larger standard deviation also means that there will be a number of cabbages which are significantly bigger than most of John’s.
- John’s cabbages are smaller on average, but only by a little bit (one quarter inch). Meanwhile, the smaller standard deviation means that the sizes of his cabbages are much more predictable. The spread of sizes is much less, so they all end up being closer to the mean. While he may not have many extra large cabbages, he will not have any that are excessively small either, which may be better for any stores to which he sells his cabbages.
Review
- Two bus companies run services between Los Angeles and San Francisco. Inter-Cal Express takes a mean time of 9.5 hours to make the trip, with a standard deviation of 0.25 hours. Fast-Dog Travel takes 8.75 hours on average, with a standard deviation of 2.5 hours. If Samantha needs to travel between the cities, which company should she choose if:
- She needs to be on time for a meeting in San Francisco.
- She travels weekly to visit friends who live in San Francisco and wishes to minimize the time she spends on a bus over the entire year.
For problems 2-6, suppose you have a collection of data points for which you have already found the mean, median, mode, range, variance, and standard deviation. Then, you collect two new data points—one that is higher than any of the values in the original set, and one that is lower than any of the values in the original set.
- Based on just this information, can you tell what will happen to the mean value of the data set when these new points are added? (In other words, can you say anything at all about whether the mean will or won’t increase, decrease, or stay the same, or do you not have enough information to tell—and if not, what additional information would you need?)
- Can you tell what will happen to the median value?
- Can you tell what will happen to the mode? (Assume the original data set has only one mode.)
- Can you tell what will happen to the range?
- Can you tell what will happen to the variance and standard deviation?
For problems 7-11, suppose that instead of collecting two new values for your data set above, you have only collected one new value—one that is higher than all the values in the original set.
- Now can you tell what will happen to the mean value?
- Can you tell what will happen to the median value?
- Can you tell what will happen to the mode?
- Can you tell what will happen to the range?
- Can you tell what will happen to the variance and standard deviation?
Finally, for problems 12-16, suppose that instead of being higher than all the values in the original data set, your new value is somewhere in the middle of the original data set. Specifically, suppose it is higher than the mean, lower than the median, and equal to the mode.
- Now can you tell what will happen to the mean?
- Can you tell what will happen to the median?
- Can you tell what will happen to the mode?
- Can you tell what will happen to the range?
- Can you tell what will happen to the variance and standard deviation?
Vocabulary
| Term | Definition |
|---|---|
| Chebyshev's theorem | Chebyshev’s Theorem gives us information about the minimum percentage of data that falls within a certain number of standard deviations of the mean, and it applies to any population or sample, regardless of how that data set is distributed. |
| descriptive statistics | In descriptive statistics, the goal is to describe the data that found in a sample or given in a problem. |
| deviation | Deviation is a measure of the difference between a given value and the mean. |
| Dispersion | The dispersion is equal to the range of a given set of data. |
| Interquartile range | The interquartile range is the difference between the third quartile and the first quartile (Q3-Q1). |
| Range | The range of a data set is the difference between the smallest value and the greatest value in the data set. |
| Sampling error (random variation) | Sampling error occurs whenever a sample is used instead of the entire population, where we have to accept that our results are merely estimates, and therefore, have some chance of being incorrect. |
| standard deviation | The square root of the variance is the standard deviation. Standard deviation is one way to measure the spread of a set of data. |
| variance | A measure of the spread of the data set equal to the mean of the squared variations of each data value from the mean of the data set. |
Additional Resources
Video: Algebra II: Mean and Standard Deviation
Practice: Measure of Spread or Dispersion
Real World: How Smart Was Einstein?