
10.5: Modeling with Regression
- Page ID
- 5801
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Modeling with Regression
Linear correlation is the simplest type of relationship between two variables. Your calculator has the power to use a variety of different function families to find other relationships and create many different types of models. How do you choose which function family is best for a given situation?
Modeling with Regression
Once you understand how to do linear regression with your calculator, you already know the technical mechanics to perform other regressions in the [STAT] [CALC] menu. The most common regressions correspond to the function families.
- QuadReg - Quadratic function family
- CubicReg - Cubic function family
- QuarticReg - Quartic function family or 4th degree polynomial
- LnReg - Natural Log function family
- ExpReg - Exponential function family
- PwrReg - Power function family
- Logistic - Logistic function family
- SinReg - Sinusoidal function family.
When you perform these types of regressions, it will be incredibly important for you to interpret and explain parts of the graph. Here are some points to keep in mind:
- The y-intercept may have a particular meaning that may or may not be reasonable.
- When you use your model to make predictions it is important for you to remember the relevant domain of your model. If your data is about elementary school students then it might extend to middle and high school students, but it might not.
- The calculator may produce a correlation coefficient for each of these non-linear regressions, but you should be very careful. Technically, the correlation coefficient is only supposed to be calculated with linear regression, so the calculator is doing some fancy linearization to produce it. You can learn more about this process in future statistics courses.
In general, at this point you should use your best judgment when choosing a function family to model a given set of data and deciding how good a fit the model is based on context.
Take the following data about SAT scores and number of hours slept the night before.
| # Hours Slept | SAT Score |
| 8.5 | 1840 |
| 10.9 | 1510 |
| 9.1 | 1900 |
| 7.5 | 2070 |
| 7.2 | 1550 |
| 6.0 | 1720 |
| 2.3 | 840 |
| 5.5 | 1230 |
Let x be the number of hours slept and y be the SAT score.
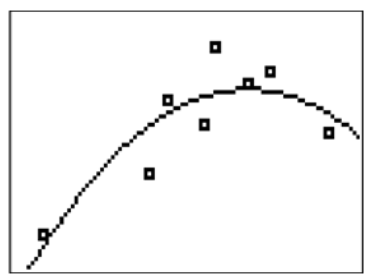
After plotting the points, you should choose a function family to use as a model. In this case, it would be appropriate to try a quadratic relationship.
CK-12 Foundation - CCSA
A quadratic model makes sense because there seems to be a peak in the model and in the data around 8.5 hours of sleep. It makes sense that someone who does not get enough sleep will do worse and someone who gets too much sleep might also do worse.
From the regression model, we can answer the following questions:
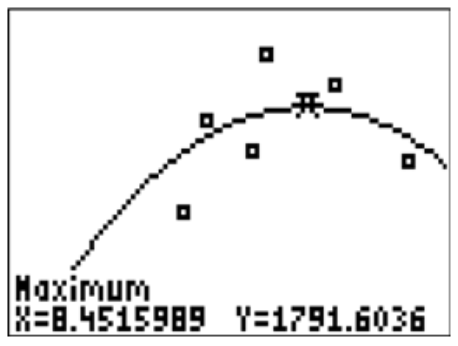
- What is the perfect amount of sleep to get before the SATs?
-
Use the calculator to find the maximum of the parabola. The x coordinate represents the “perfect” amount of sleep.
-
CK-12 Foundation - https://www.flickr.com/photos/cjdjkobe/5624576451 - CCSA
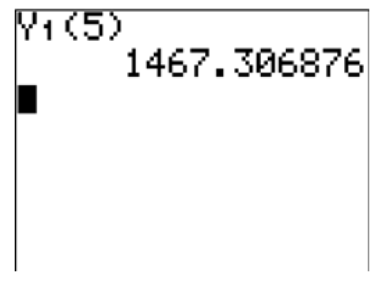
2. Calculate the score you are predicted to get if you get 5 hours of sleep.
-
You can substitute x=5 into the equation, or you can let the function you created and stored in y1 simply act on the 5.
CK-12 Foundation - https://www.flickr.com/photos/cjdjkobe/5624576451 - CCSA
3. What is the relevant domain of the model?
- The relevant domain is between about 2 hours and 10 hours of sleep. Beyond those numbers of sleep, the model will probably not make a whole lot of sense. How could someone get negative hours of sleep?
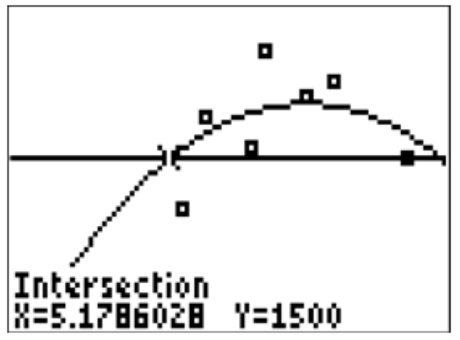
4. The average SAT score is about 1500. According to the model, what amount of sleep predicts this score? Does this number represent the average number of hours that people sleep before the SATs?
-
You can substitute ŷ =1500 into the equation and solve for x using the quadratic formula, or you can graph the line y=1500 and use the calculator to produce the two intersecting points.
CK-12 Foundation - https://www.flickr.com/photos/cjdjkobe/5624576451 - CCSA
5.1786 hours and 11.7246 hours are the number hours of sleep that predict a score of 1500.
When using the model in this direction, the results do not make as much sense and you need to be extremely careful about what you say.
5. Compare the actual and predicted score for someone with 6 hours of sleep.
- The actual score for someone who got 6 hours of sleep can be found in the original data to be 1720. The model predicts 1627.9970. The difference between the model and what actually happened is 1720−1627.9970=92.003
Examples
Example 1
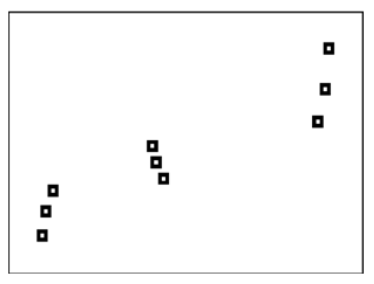
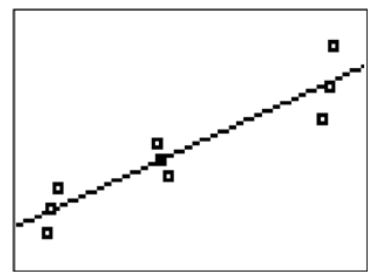
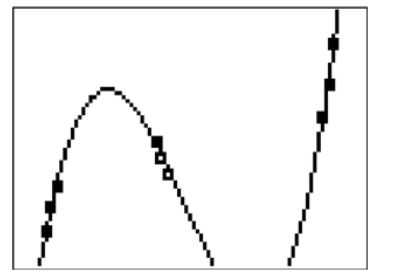
Earlier, you were asked how to decide which function family to use for the a given situation. For some data sets it is possible to use a polynomial or other complicated shape to exactly intersect every data point. The downside is that the model will miss the overall relationship. Consider the following data and modeling a linear relationship or cubic relationship.
CK-12 Foundation - CCSA
CK-12 Foundation - CCSA
CK-12 Foundation - CCSA
The linear relationship describes the upward positive relationship in the data very well, but some points are slightly off of the line. The cubic relationship is much more accurate at the specific data points; however, there are features of the cubic relationship that differ significantly from reality when interpreted in context. In order to choose the best regression model you need to use context clues and the reasonableness of the various features of the model that fit each situation.
Example 2
Use your knowledge of function families to predict the best model for each of the following scatterplots.
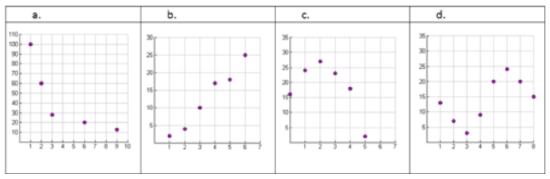
CK-12 Foundation - CCSA
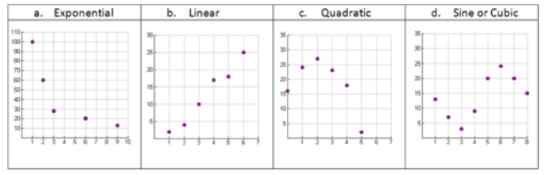
CK-12 Foundation - CCSA
Example 3
The following data represents the height of an elephant over time. Determine the best regression function to use and determine its equation.
| Age(Years) | Height (ft) |
| 0 | 2 |
| 2 | 2.8 |
| 4 | 4 |
| 8 | 7.5 |
| 12 | 10 |
| 16 | 10.4 |
| 20 | 10.45 |
Logistic is the best function family because it levels off over time indicating that the elephant ceases to grow once it matures.
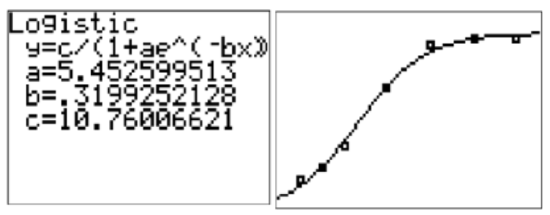 CK-12 Foundation - CCSA
CK-12 Foundation - CCSA
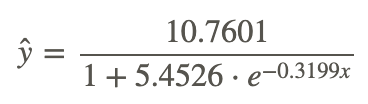
Example 4
The following data represents the speed that Ben can kick a soccer ball at different ages. Determine the best regression function to use and determine its equation.
| Age(Years) | Speed (mph) |
| 4 | 15 |
| 10 | 32 |
| 20 | 65 |
| 30 | 70 |
| 50 | 45 |
| 60 | 35 |
The best regression to use is a quadratic relationship because when Ben is little he cannot kick the ball very fast and when he is old he also cannot kick the ball very fast. Ben can kick the ball the fastest when he is an adult between the ages of 20 and 40.
ŷ =−0.05981x2+4.0679x+0.6191
Example 5
What are two weaknesses and two strengths of the model used to predict Ben’s kicking speed from Example 4.
One strength is that a quadratic model correctly describes the peak of kicking speed occurring in the middle of Ben’s life. A linear regression might forecast Ben’s kicking speed increasing forever and a logistic regression might forecast Ben’s kicking speed always staying fast despite his old age. A second strength of the model could be the y-intercept of 0.6191. Even though this number is not really in the relevant domain, it implies that as a newborn baby Ben could kick the ball very slowly which is arguably true.
One weakness of the model is that it predicts that Ben will kick the ball at 0 miles per hour at age 68.1660. This implies that Ben will not be able to kick the ball at all which isn’t necessarily true.
A second weakness of the model is that it predicts negative speed at either age extreme which doesn’t make sense. A better model would be flat at 0 when Ben is born and also at the end of Ben’s life when he is no longer able to kick the ball.
Review
The table below shows the average height of an American female by age.
| Age (Years) | Height (inches) |
| 2 | 34 |
| 8 | 50 |
| 11 | 57 |
| 15 | 63 |
| 23 | 64 |
| 35 | 64 |
1. Determine two different equations that model the height over time using two different function families.
2. Which function is a better fit for this data? Why?
3. Use both equations to predict the y-intercepts. What does the y-intercept represent in each case? Are your predictions reasonable for this part of the graph?
4. Use your “better fit” equation to predict the height of a 70 year-old woman. Is your prediction reasonable for this part of the graph? Why or why not? What do you really need your model to do for the domain [16,100]?
Alice is in Wonderland and drinks a potion that approximately halves her height for each sip she takes, as shown in the table below.
| # of sips | Height (inches) |
| 0 | 60 |
| 1 | 29 |
| 2 | 16 |
| 3 | 8 |
| 4 | 4.1 |
5. Do an exponential regression to determine an appropriate model. What is the equation?
6. Explain why exponential regression is a good choice in this case.
7. How many sips did she take if she is 2 inches tall?
8. How tall will she be if she has 6 sips?
A rumor is spreading around your 400 person school. The following table shows the number of people who know the rumor each day.
| Day | # of people who know the rumor |
| 1 | 2 |
| 2 | 8 |
| 3 | 29 |
| 5 | 161 |
| 6 | 372 |
| 7 | 378 |
| 8 | 391 |
9. Use logistic regression to determine an equation that models the number of people who know the rumor over time.
10. Why is the logistic model appropriate in this case?
11. Use your regression equation to predict the time when only one person knew the rumor. Does this make sense?
The data table below represents how the tide changes the depth of the ocean water at a beach. At a certain place in the water, a scientist measures the depth of the water for ten consecutive hours.
| Hours | Depth of Ocean Water (ft) |
| 0 | 9 |
| 1 | 11.2 |
| 2 | 12.4 |
| 3 | 12.9 |
| 4 | 12.5 |
| 5 | 11 |
| 6 | 8.9 |
| 7 | 7 |
| 8 | 5.5 |
| 9 | 4.9 |
| 10 | 5.4 |
12. Choose the function family that is the best model for this situation and determine the regression equation.
13. Use your regression equation to predict the depth of the water at 10 hours. What is the difference between the actual depth from the data and the predicted depth from your equation (residual)?
14. Do a cubic regression on the calculator. What is the cubic regression equation? Is this a better or worse model than the model you originally chose?
15. Why might statisticians do modeling with regression for their data?
Vocabulary
| Term | Definition |
|---|---|
| linear correlation | Linear correlation is a measure of the strength of the linear relationship between two random variables. |
| linear regression | In statistics, linear regression is a process that attempts to model the relationship between two variables by fitting a linear equation to the data. |
| residual | The residual is the difference between actual height and predicted height using a model. |
| Scatterplot | A scatterplot is a type of visual display that shows pairs of data for two different variables. |